An Agentic Learning Loop
How My Agents Stopped Repeating My Mistakes
Key Takeaways
- The bottleneck in agentic work is institutional context and memory, not model capability. Whether agents can read what your organization already knows directly influences speed and efficacy
- A static memory layer is half a system. The value compounds when agents write lessons back as they happen, making the agents part of the learning loop
- Postmortems identify patterns, patterns become policies. A rule earns its place when a second project hits the same failure; one incident is bad luck
- Most of this work doesn’t look like AI work, it looks like a documentation cleanup project. The content already exists, we just need to make it accessible to the bots
I recently built a venue-search feature I really love. I can save venues as “favorites”, and then the app sends me a notification anytime a new show is announced at one of those venues.

A few days later I deployed an update and the feature was gone. It looked like the deploy worked fine, but the feature had disappeared. I was able to restore the feature pretty easily, but I lost an hour and that was enough to make me look into a more scalable process fix.
I spend most of my day on transformation work with clients, and safe, scalable AI that operates within rules is top of mind for many of them. Organizations have spent decades learning how to share standards across humans. Many are still figuring out how to share them with Bots, especially when humans and Bots work on the same teams. I wanted to live with that problem before I kept prescribing solutions for it. What follows is what came out of running the experiment on myself, in a side project where the stakes are low and the feedback loop is fast (and sometimes painful).
Working with agents has three failure modes that get worse as you scale:
Sessions start blank. Every conversation begins without knowing your AWS account, your deploy steps, your project conventions. Agents guess, and guesses produce code that works in test and breaks on something specific to your setup.
Conventions drift between projects. Past a few repos, the rules you keep in your head start to diverge from project to project. Different agents read different versions of the same standard.
Lessons evaporate. What you learn in one session disappears at session end. The same mistake happens again later in a different repo, with a different agent that has no memory of the first time.
These are all structural memory problems, not issues with the models. The setup that follows is my answer to all three, and a preview of what I think most enterprises will have to build over the next few years.
The architecture
The split comes from a basic distinction. What’s true about how I work stays constant across projects, what’s true about a project changes per repo, and what’s true about a single repo lives with the code itself. Three layers, each with a different lifespan.
- Personal Context Portfolio (PCP) — the universal layer (code on GitHub)
- Cross-project preferences, rules, communication style, AWS standards, deploy hygiene
- The index pointing to each project’s notes
- Read by every agent at session start
- Lives in S3, behind an MCP server
- Project-specific notes — the per-project layer
- Architecture, backlog, change log, environment status, gotchas
- The source of truth for “what’s true about Project X”
- Repo-level notes — the per-repo layer (Claude.md, Agents.md, etc.)
- Deploy commands, env vars, local gotchas
- Auto-loaded by Claude Code when working in the repo
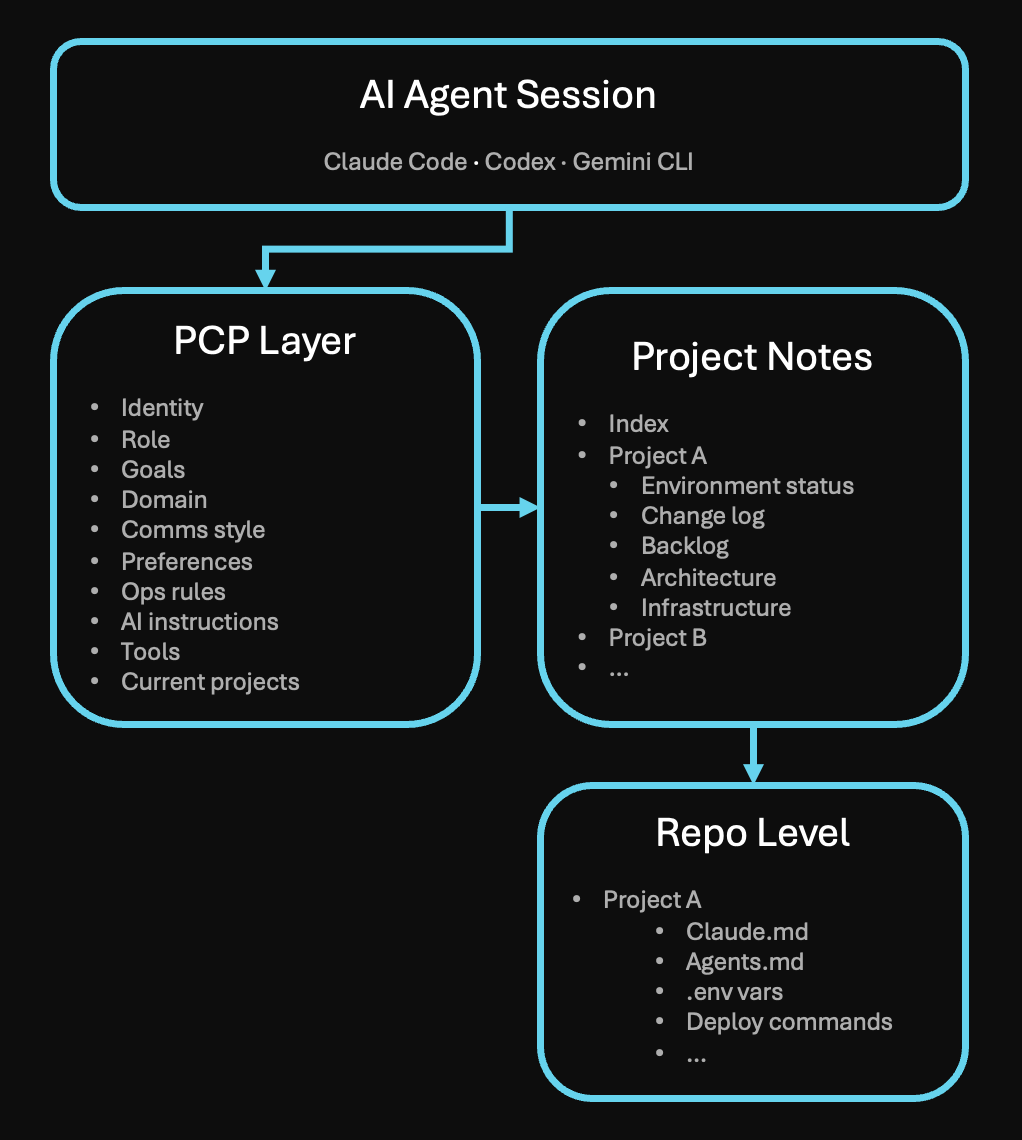
PCP is read first because it’s also the index, telling the agent where each project’s notes live. The MCP server setup is especially useful for when I’m working across agents (Claude, Codex, Gemini CLI, etc.) and they all need the same source. Without a stable endpoint, I’d be back to one context island per tool.
The whole PCP setup is about 200 lines of Python on a single Lambda, with the content in S3. The setup itself is quick; once deployed, you can start capturing rules with any Bot in any session.
The loop that compounds
I’ve tweaked the structure over time as my Bot friends and I have learned how to work with each other, but the one change that really compounded was adding a rule for them to document lessons learned at the end of a session.
One of the PCP files, operational-rules.md, contains principles I want every agent to internalize before doing anything in any of my projects; each one is anchored to a specific incident. The first reads like this:
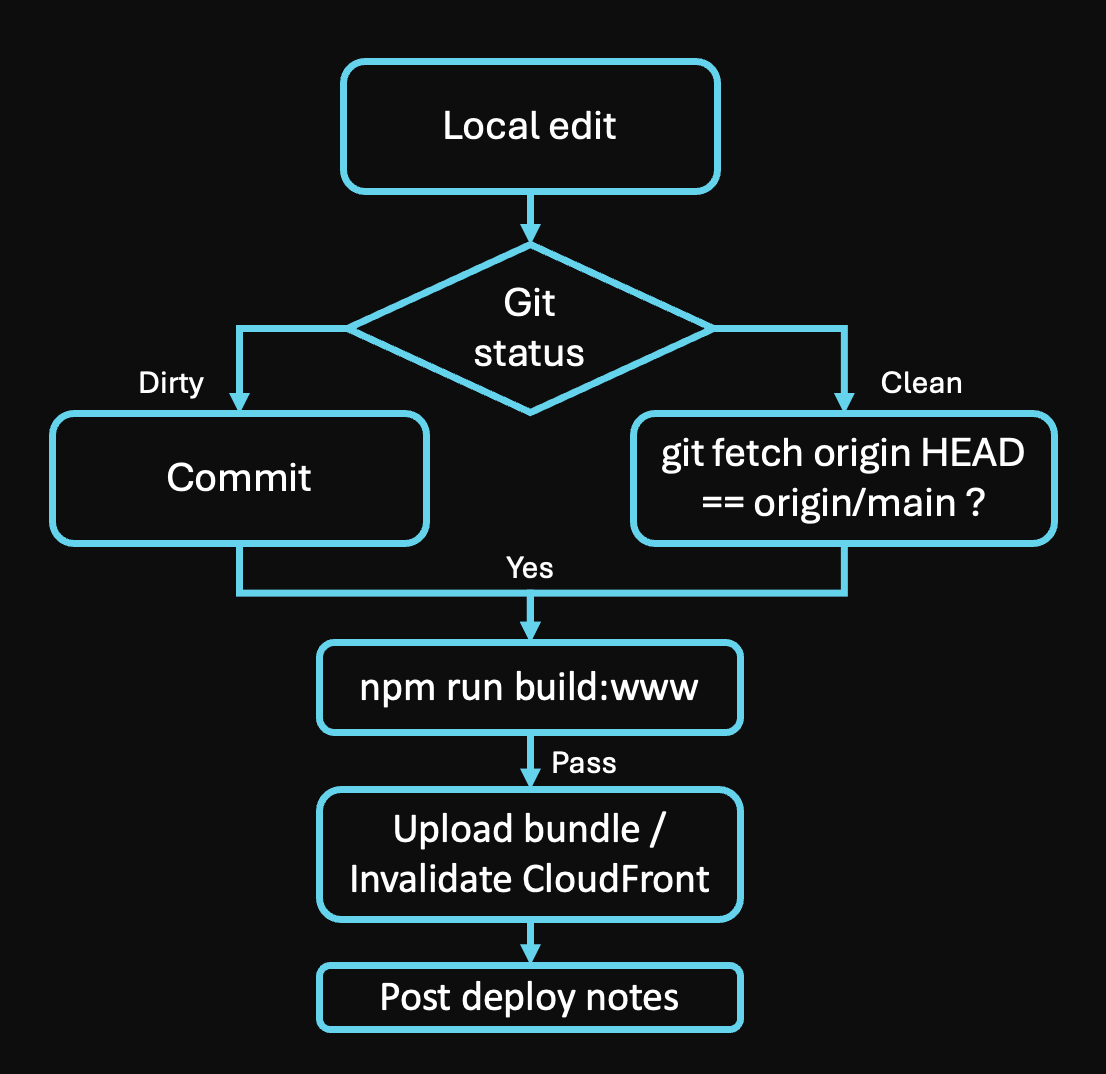
Principle 1: Deploy only from a clean, committed source.
git statusmust be clean before any deploy. Applies to every deploy of every project.
Incident 1 — TixTrk venue search wipe.
Incident 2 — TixTrk repeat. Build-time guardverifyGitSync()shipped in response.
The full operational rules list, in shorthand:
1. Deploy only from a clean, committed source
2. Unique-identifier registries are write-once (TestFlight builds, ECR tags)
3. Worktree audit when live state ≠ expected
4. Replicate gitignored config into every worktree
5. Prod data mutations: dry-run → review → snapshot → apply
6. Read SECURITY_COMPLIANCE.md before suggesting infra cuts
7. Snapshot before any "replace-style" config APIA rule is added whenever we experience a major incident, or whenever a nuisance reoccurs and deserves to be avoided in the future. Postmortems identify patterns, patterns become policies.
What makes the loop self-sustaining is that agents can write to PCP mid-session. When a capture trigger fires (a correction, an incident, a new way of working), the agent calls update_context and writes the lesson directly into the right file.
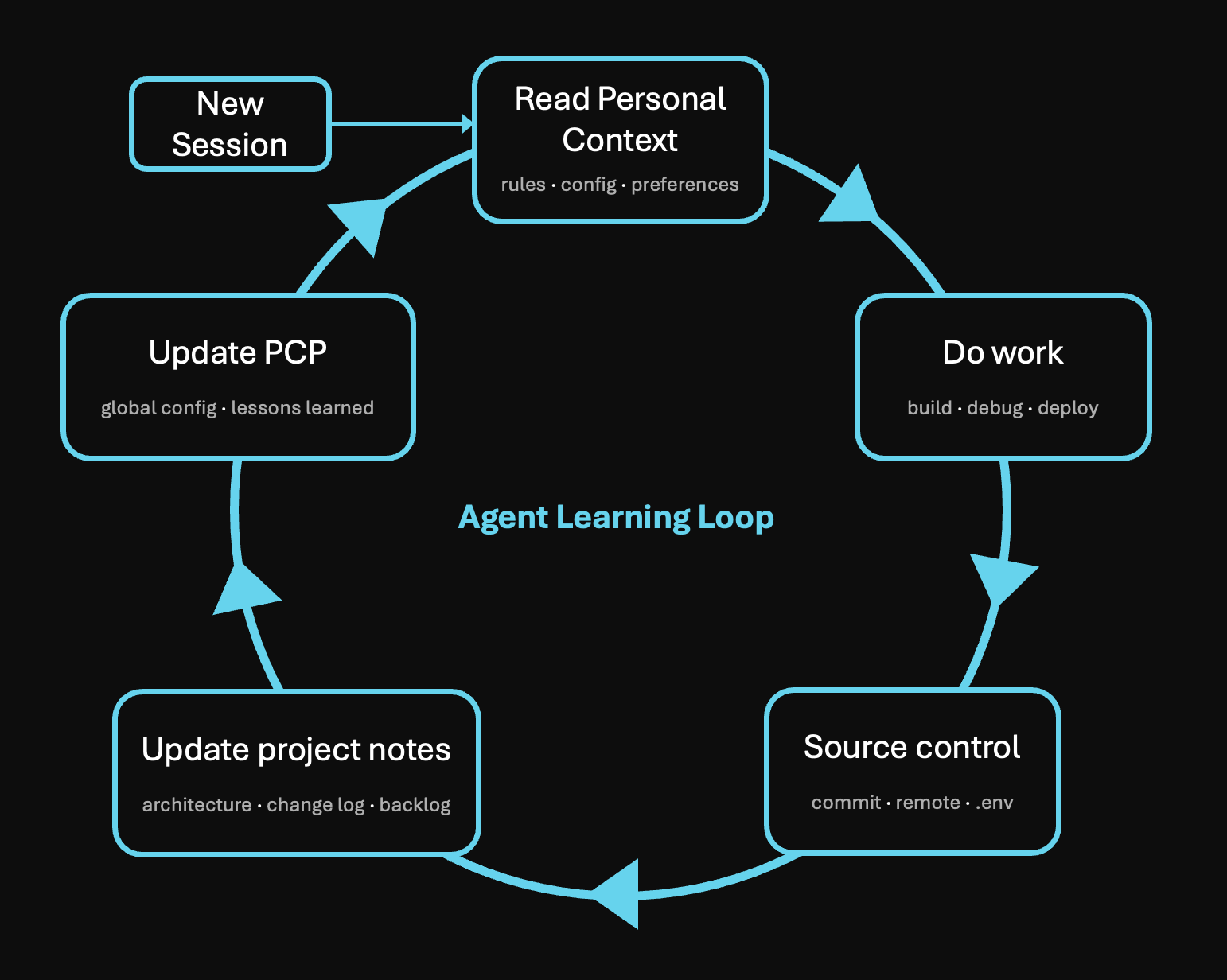
A Cognito incident is the cleanest example. I asked an agent to upgrade a user pool to a higher tier. The command silently wiped a critical config field. I caught it, restored from a backup, and within the same session the agent wrote a new principle directly into PCP. The next agent to do Cognito work, on any project, started with the snapshot-and-diff rule already loaded.
That’s the compounding part. Every session reads the accumulated wisdom, does the work, and adds whatever it learned back to the same place. The cost of writing a rule down has collapsed to roughly zero, which has been helpful as I lack deep domain expertise in everything that I’ve asked the Bot to do for me.
“Postmortems identify patterns, patterns become policies.”
What this has actually bought me
A few concrete improvements that have stuck:
- Deploys are safer and faster. TixTrk’s
verifyGitSync()build guard hard-fails any deploy from a dirty tree or wrong branch. The rule lives in PCP, but the build enforces it. Same rule, two places. The agent might forget the manual check; the build won’t. - TestFlight uploads stopped costing me cycles. Build numbers can’t be reused once submitted, even on rejection. Principle #2 means every upload bumps
CURRENT_PROJECT_VERSIONfirst. No more rejected builds because I tried to reuse a number that Apple had already consumed. - Cognito changes don’t wipe configs anymore. Principle #7 (snapshot before any “replace-style” config API) was written in the same session as the Cognito incident. The next change to any of my four pools followed the snapshot-diff pattern automatically.
- New projects start with the conventions already loaded. When I spin up a new repo, the agent’s first move is to read PCP. AWS account, git rules, deploy patterns, agent preferences — all in the conversation before any work happens. No re-setup, no drift.
Once a rule lands in PCP, the failure mode it captures stops repeating. That’s the proof the system is working: the second incident is what writes the rule, and there isn’t a third.
What this looks like at enterprise scale
Everything in this post is a side project. The patterns generalize directly.
The three-layer model maps directly onto how most enterprises already organize what they know:
| Layer | Use | Example |
|---|---|---|
| Enterprise Context Portfolio (ECP) | Org-wide standards: security, code hygiene, deployment standards | Engineering handbook, ADRs, governance wiki |
| Project | App/project details: backlog, architecture, change log, runbooks | Confluence, Jira, design docs |
| Repo | Deploy scripts, env vars, local quirks | README, CLAUDE.md, AGENTS.md |
A lot of this content already exists in most organizations, but it’s not always obvious and accessible to the Bots. Backlogs live in Jira. Detailed notes live in Confluence, OneNote, and README files. Code lives in git repos, but different teams use different standards for when to write tests or how to handle releases, and often learn those standards over time through ritual vs. writing them down.
None of this is broken or wrong per se, we just need to update how we design and access it for our new Bot friends.
The compounding loop is the harder thing to install. Many organizations capture lessons once, in a postmortem, and lose track of where they put them. An ECP at enterprise scale would be a system where every team’s lessons accumulate into the same readable place, automatically, in the flow of work. That’s the version I keep finding myself describing when I talk about it.
These are my personal observations from tinkering on a side project, and they don’t necessarily reflect the views of my firm. That said, we have some great AI tools and solutions, and I’d love to tell you about them.